
HTAPキャッチフレーズの背景
少し前にちょっとだけ出た HTAP というバズらなかったバズワード。 MariaDBは押している(?)。
HTAP はインメモリデータベースよりも曖昧で産業よりな言葉だ。 あいまいな言葉だけどインメモリデータベースより広く 新しいデータベース を指す用語なので今回は使ってみる。
HTAP の目標と関連実装の雰囲気をSIGMOD'17 のチュートリアルから知れる。 学術的な整理ではないし非難も多いけど、いくつかの実装へリファレンスがあり勉強のとっかかりになった。
今回は HTAP の一応の目標や出てきた背景と関連したインメモリデータベースとかの列挙をしてみる。
HTAPの背景
HTAP はラムダアーキテクチャから進歩するぞ!的なスローガンになっている。 ラムダアーキテクチャはApache StormのNathan Marzがデータを処理する流れについて提案したアーキテクチャ。 これはデータ処理基盤を表していて、バッチ・サービス・スピードと3つのレイヤ(コンポーネント)を通してクエリに応答するパターンを指す。
バッチを挟んでおり OLTP と OLAP の実行が分離されている。 HTAP ではこれら2つの処理をリアルタイムに実行することを目指している。
これが叫ばれる背景には、リアルタイムに分析したいという需要があるかららしい。 また、メモリが大きくなりコア数も大きくなり、GPUやFPGA、SSDにNVRAMなど新たなハードウェアの登場で両立しうると期待されているためだ。
メモリに全データを収められる前提なら、ページ単位の中途半端な永続化を考慮しないで済む。 そのため余計な処理を削減できる。
それらに加えて新しい計算資源を使いスループットを向上させるなど実装の選択肢も増えている。 こういったことを受けて「OLTP, OLAPと分ける時代は終わった」と宣伝すると嬉しい人たちが HTAP ってスローガンを作ったという雰囲気だ。
インメモリデータベースのしっかりしたチュートリアルとしてPaul Larsonらが書いたModern Main-Memory Database Systems, VLDB'16がある。 これは技術的な観点(要件や構成要素)を整理して、それぞれのアプローチや関連論文への参照をまとめている。 これから紹介するチュートリアルよりも短くて有意義なので読むといい。 データストレージとインデックス,並行制御,耐久性と復旧,クエリ実行とコンパイル,高可用性,HTAPなどの観点が紹介されている。
チュートリアルの要約
Hybrid Transactional/Analytical Processing: A Surveyを読んだので整理する。
このチュートリアルは次のような構造を持ってた。
- HTAPの動機や需要について
- データベースの多様化について
- OLTP/OLAPの提供形態について
- 分類とそれぞれの具体例
HTAPの動機や需要について
ここ数年、リアルタイムに巨大データの解析することが求められてきている。 既存のデータベース実装では満たすことが難しい。
データベースの多様化について
このチュートリアルはデータベースの現況をCIDR'05 Stonebrakerを背景に説明していた。 その見方では、データベースはOLTP,データウェアハウス(OLAP),ストリーム処理など用途ごとに実装が多様化する(している)というものだ。
StonebrakerはCIDR'05,CIDR'07を通じて、データウェアハウス,ストリーム処理,科学技術計算などで既存のデータベース(OLTP)のエンジンとは別の最適化が適していると主張していて、単一のデータベースによるデータ集約したアプリケーション実装は時代遅れと指摘した。
CIDR'05以降にいろいろなデータベース実装が出ていて、 チュートリアルではそのようなカテゴリとしてcolumn-oriented OLAP,In Memory OLTP,NoSQL,SQL-on-Hadoopの4つ紹介されている。
| チュートリアル内での分類 | 実装名 |
|---|---|
| column-oriented OLAP | BLU, Vertica, ParAccel, GreenPlumDB, Vectorvise |
| In Memory OLTP | VoltDB, Hekaton, MemSQL |
| NoSQL or KVS | Voldemort, Cassandra, RocksDB |
| SQL-on-Hadoop | Hive, Big SQL, Impala, Spark SQL |
チュートリアルではcolumn-oriented OLAP,In memory OLTPをそれぞれ第2世代のOLAP,OLTPと書いていたけれど、なにが第2世代だという感じ。普通にデータベースエンジンの最適化が進んだ感じに思え敢えて分ける必要性がなさそう。(一応、multi-core,multi levels of memory caches,large memoriesを活かしていると書かれてはいる)
後ろの2つはRDBMSの最適化の流れと少し違って、データサイズが大きなWebアプリケーションを背景に持ってる。 書き込みのスループットへの対応にトランザクションを諦めてスケールアウトしたNoSQLと、蓄積されたデータの解析を分散処理(Hadoop)で実行してきた。Hadoopなどの分散処理で利用するデータはファイルに格納される。 HadoopなどをOLAPとして使うために、Parquet,ORCFileなどの列指向フォーマットを使うことが一般的になった。
OLTP/OLAPの提供形態について
OLTP/OLAPの組み合わせを提供する方法として下を並べてた。だから何だという感じではある。
- 以前のデータベース・データ処理基盤の変更する
- 以前のデータベース・データ処理基盤を組み合わせる
- 以前とは別に新たに実装する
分類とそれぞれの具体例
このチュートリアルでのHTAPなシステムの分類に有用性はない。 処理エンジンとストレージレイアウトでOLAP/OLTP向けコンポーネントを分離してるか統合してるかで考えている。 チュートリアルに従った分類を表に起こすと下になる。
| single system | separate OLTP and OLAP | |
|---|---|---|
| separate data organization | SAP HANA, Oracle TimesTen, MemSQL, IBM DashDB, HyPer(, ScyPer), Pelaton | KVS(e.g. Cassandra) + ETL(e.g. to ORC/Parquet HDFS) + SQL-on-Hadoop |
| same data organization | $H^2TAP$, Hive, Impala+Kudu | SAP HANA Vora, SnappyData, SparkConnector(HBase, Cassandra), Hive, Impala, IBM Big SQL, Actian Vector H, Splice Machine, Apache Phoenix, Wildfire |
他にMonetDB, Vertica, Silo, VoltDB, Hekatonが既存のDBでHTAPをサポートするように発展したと言及されていたが、チュートリアルで分類されてなかった。
チュートリアルではそれぞれのカテゴリごとに個別の実装について補足している。 ETLを挟んだラムダアーキテクチャが含まれてるし KVS + ETL + SQL-on-Hadoop がありつつ Hive もあったりと謎い。
チュートリアルの分類に従う必要を感じなかったので、従わずに紹介された実装や論文から下のものを補足する。
- H-Store
- Silo
- Hekaton
- HyPer
- Peloton
- Hadoopエコシステムを使う方々
VoltDB(H-Store)
H-StoreはStonebrakerがThe End of an Architectural Era, VLDB'07という論文で提案したOLTPの実装。
前述した論文で指摘したようにRDBMSの実装がOLAP,Streamingとエンジンの最適化と多様化が進むと予想していて、それを背景に改めてOLTPを再設計しましたよという感じ。のち(2016)に商用化してVoltDBとなる。
テーブルをパーティショニングしてノード分散している。トラザクションはワンショット(ストアドプロシージャ)としてデータベース内で実行される。ノードをまたがるトランザクションはコーディネータに委託して衝突の可能性を事前に排除して実行する方式みたい。(地理分散とかノード分散の話を知りたくなった時に改めてちゃんと読んだ方が良さそう)
Rethinking Main Memory OLTP RecoveryでVoltDBのリカバリについて評価している。従来のARIESスタイルじゃなくてコマンドロギングを採用しているとのこと。ちゃんと読めてないので触れられない。 (ちなみに1コア1秒あたり4K以上トランザクションを捌いてるのを十分大きいスループットとしてたので、目安として考える)
Silo
SiloはSOSP 2013でのSpeedy Transactions in Multicore In-Memory Databasesで論文になっている。
メニーコアを活かすOLTPでスループットがコア数に対してスケールすることを示した実装で多くの論文(HyPer,TicToc,Cicada,Foedus,Sundial,ERIMA,MOCC,…)に影響を与えている。
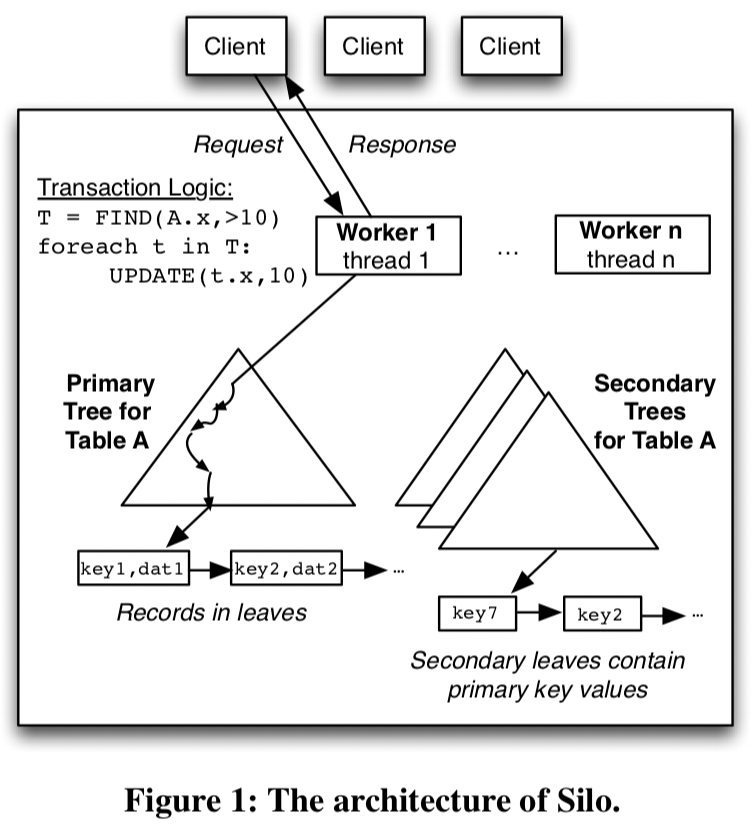
クライアントからワーカーがワンショットトランザクションを受け取り実行する。
コミットプロトコルはOCCをベースにID割り当てでロックを必要としないように工夫している。 インデックスはMassTreeベースの実装を採用している。(論文ではツリーにコミットプロトコルを実装したけど他のデータ構造でも適用できるよって書かれていた。)
トランザクションの実装の中心にはコミットプロトコルとテーブルを実装するデータ構造がある。
Siloのテーブル(とセカンダリインデックス)はMassTreeベースとなっている。 リーフノードは以下の情報を含んだレコードになっている。
- レコードデータ
- 前バージョンのレコードへのポインタ
- 後述するトランザクションID(TID)
このTIDは64bit整数型で制御ビット(下位3bit)が含んでいる。 これは並行制御を簡単にするためらしい。おそらくバージョンの確認と制御状態を同時に取得でき扱いやすくなるため。
トランザクションの制御や耐久性の実現にはエポックと呼ばれる単調増加する値が利用される。
| 用語 | 説明 |
|---|---|
| エポック | 障害復旧,ガベコレ(削除済みレコードの除去),読み込みスナップショットなどで利用する単調増加する値 |
| トランザクションID(TID) | トランザクションのIDで後述する方法で計算される |
エポックは専用のスレッドでインクリメントしていく。 一方、トランザクションID(TID)はトランザクションを実行しているワーカーがコミット時に以下の条件を満たすように割り当てる。
- トランザクション内で読み書きしたレコードのTIDよりも大きい
- ワーカーが発行したTIDよりも大きい
- 現在のエポックの範囲内
これらを使ってコミットプロトコルが組まれている。このプロトコルに基づいてRead/WriteやDelete,RangeQueryが実現される。コミットプロトコルはS2PLを元にしたOCCでSerializableを満たすスケジュールのみが生成される。
先ほどの規則でTIDを与えると同一ワーカー内のトランザクションは順序が決まる。 またデータの読み書きを通じて発生した依存関係を満たすようなIDが振られるため衝突が起きないことが決まる。 そしてエポックが異なるトランザクションには前後関係が必ずある。
耐久性の実現には3番目の性質が関わる。あるトランザクションの完了をクライアントに通知した後の障害は復旧できないとならない。簡単にログについて説明する。
ワーカーはトランザクションのコミット処理が終わるとREDOログをロガーのバッファに追加する。ロガーは複数あり幾つかのワーカーを担当してて構わない。ただしワーカーは複数のロガーにREDOログを登録することはしない。
ロガーは一定条件のもとでバッファを永続化する。その際にロガーはワーカー毎の最後のTIDを把握しておく。 これによりロガーが書き込み中のエポックを判断できる。 全ロガーの完了済みエポックに属するトランザクションについてクライアントに完了を通知すれば、通知後に障害がおきても必要なREDOログが永続化されていることが保証される。複数のロガーが並列で書き込んでも問題は起きない。
Hekaton
Hekaton: SQL Server’s Memory-Optimized OLTP Engine, SIGMOD ‘13としてMicrosoftが提出さしたデータベース。 当時の既存のインメモリデータベースと違い、トランザクションの並列性を高めるためにデータをパーティショニングせず、ラッチフリーなデータ構造とMVCCベースのプロトコルを採用することで図った。 高速化の原則として上記の他に、SQLの実行にコンパイルされたバイトコードを使うこと、メモリを前提としたデータ構造を採用することを挙げていた。
SQLの実行計画を中間表現(Mixed Abstract Tree(MAT))に変換してHekatonのメタデータを加えて中間表現(Pure Imperative Tree(PIT))を作ってからCを生成するらしい。(HyPerはLLVM中間表現を利用している) Mixed なのはバイトコードが生成されるのは Hekaton だけど SQL Server に組み込まれているから。 PIT が生まれるのは普通のSQLとHekaton用のT-SQLとの型の不一致とか色々を吸収するためらしい。
MVCCの実装については別の論文(High-Performance Concurrency Control Mechanisms for Main-Memory Databases, VLDB'12)がある。 (補遺もある)
SQL Serverに統合されていて部分的にHekatonの利用ができるようになっている。
Real-Time Analytical Processing with SQL Serverって論文で Hekaton のように SQL Server に統合された OLAP が説明されている。
HyPer
HyPerはミュンヘン工科大学で始まったプロジェクトで2016年にTableauに買収され組み込まれたDBMS。
2011年に公開された論文などで説明されているプロトタイプでは、MMU+OSの提供するコピーオンライト(COW)を使ってスナップショットを提供していた。 しかし2015年にSIベースのMVCCに基づくアーキテクチャに大きく変更し論文を出している。
チュートリアルではseparate data organizationに分類されているが、これはCOWに頼った古いアーキテクチャに基づいて判断していると考えられる。
新しい方式は、SIベースのMVCCでserializableを提供している。 スナップショットの提供のためにStartTime,トランザクションID,CommitTimeと3つのタイムスタンプを使う。 トランザクションの実行中にUndoバッファを作成し、これをスナップショットとバリデーションに利用している。 コミット時にバリデーションをすることで、Read Only AnomaryとWrite Skew Anomalyを避けている。
バリデーションではトランザクション中で読み込みに利用した述語を木構造で保存した Predicate Tree(PT) と直近のコミット済みトランザクションが保存されてる recentlyCommited テーブルを利用している。 コミット済みの変更レコードを PT に通して読み込み履歴があった場合にアボートしている。
バリデーションが成功後にRedoログを書き出してデータベース内のトランザクションIDをCommitTimeに書き換えることでトランザクションを完了する。 このアーキテクチャではUndoログをバリデーションでしか使っていない。 同様の方式でOLTP,OLAPを統合しているデータベースとしてOctopusDB:Towards a one size fits all database architecture, CIDR'11をこの論文内で挙げていた。
HyPerはデータベースに関するプロジェクトで関連論文としてデータベースの色々なコンポーネントの実装提案をしているので素人としては全体を眺められて勉強になる。
- クエリ実行計画最適化
- 更新処理の並行制御(コミットプロトコル)
- インデックスの実装(とその並行実行)
- ストレージレイアウト
この中でインデックスの同期実装に際してARTというTrie木を提案している。 これはメモリ効率の良いTrie木だ。ARTの面白いところはメモリ消費量が小さくなるように、子ノード数に合わせてノードのデータ構造が4種類あるところ。
別の論文(DaMoN'16)で、このARTの並行制御について楽観的ロックとREAD-OPTIMIZED WRITE EXCLUSION(ROWEX)という2方式を実装・評価している。 Trie木は含有するキー集合に対して構造が一意に決まるため並行制御と相性がいいと書かれていた。
またストレージレイアウトの論文では push down をサポートしたParquetのようなカラム指向のデータレイアウトを説明していた。
Peloton
PelotonはThe Self-Driving Database Management System, CIDR'17って論文が出されているデータベースで実装も公開されている。オペレーションとか含めて諸々を自動化したいって実装みたい。そのなかでOLAP,OLTPのワークロードも予測して対応することを考えていた。ディープラーニング使うよって書いてあった。 すでにプロジェクトは停止してて、彼らは2つめのシステムに取り組んでいるらしい。
Hadoopエコシステムを使う方々
いきなり雑になってしまったが、 HTAP としてカテゴリ分けられた Hadoop エコシステムを利用してるものを紹介しておく。
Vector HはSQL-on-Hadoopの新実装で効率的に更新できる列指向ストレージとしてPositional Delta Trees(PDTs, SIGMOD ‘10)を使ってる。(PDTsはHyPerからも参照がされていて、使ってないけど使うともっと良くなるはず的なことが書かれてた気がする) 読んでないけどパフォーマンス評価にHAWQ, Impala, SparkSQL and Hiveをぶつけてるみたい。
SnappyDataはGemFire(Apache Geode)をOLTPに使いSparkエコシステムをOLAPに使う。
Splice Machine, PhoenixはHBase上で動くSQLレイヤになっている。
WildfireはParquet(?原論文だとPAX layoutらしい)+Sparkエコシステムをつかって作られている。Spark SQLを使っているとのこと。
他にも Impala+Kudu とかもある。 (KuduはHDFSの代替で書き換えが高速な列指向DBという感じ。パーティショニングとレンジによるプライマリーキーを提供していて Cassandra に似てるなぁと思った。文中では Cassandra と異なりって書かれてたので読み返す必要がありそう。)