
DDDからみた連携パターン(その他)
去年の夏前くらいにDDDまわりの勉強していた。でこのメモを書いていたので少し直して晒してみる。 前回の続編。
ソフトウェアアーキテクチャや設計論はたくさんあってややこしい。なので自分なりに整理している。 DDD本で出てきた大規模構造やIDDD本で紹介された 連携パターンとしてのアーキテクチャ を列挙する。
大規模な構造とアーキテクチャ
戦略的モデリングはコンテキスト同士の関係を扱う。 なので前に触れたようにコンテキスト間の依存関係や連携についても扱うが巨大なモデルをどのように多数のサブコンテキストとして組み立てるかについても考える。
DDD本では巨大なドメインモデルを組み立てるのに使えるパターンを大規模構造と呼んで紹介している。 一方でIDDD本ではもっと技術的な側面に注目してソフトウェアアーキテクチャを列挙している。
DDDからアーキテクチャをどう使うかが気になっているのでIDDD本で紹介されるものを扱う。 DDD本で扱う大規模構造は戦略的モデリングを整理する際に扱うことにする。
連携パターンとしてのアーキテクチャ
IDDD本で紹介されている連携パターンとしてのアーキテクチャを(SOAを除いて)紹介する。 IDDD本ではRESTとデータファブリックについては寄稿という形式で掲載している。 サービスオリエントアーキテクチャ(SOA)は別の時に書く。
| アーキテクチャ名 | DDDの用語を用いた概要 |
|---|---|
| REST | HTTP上でサービスをリソースとして表現する |
| CQRS | 操作と参照を分離する |
| イベント駆動 | イベントの発行、検出と消費を軸に構成する |
| データファブリック | 処理を分散実行してくれる基盤を利用する |
特にデータファブリックの説明についてはもやっとするが大きくはこれらが説明されていた。
REST
RESTfull HTTPのこと。 HTTP上でサービスをリソースとして抽象化する。
ステートレスでセッションをまたいだ状態管理はクライアントの責任となる。 HTTPサーバーによる状態管理が不要となりスケールアウトさせやすいというのが当初の利点。
設計にあたっては、サブコンテキストをRESTfull HTTPとして公開するときにやみくもに内部状態を晒さないように注意する。 またAPIのインタフェースを更新しやすく準備しておくことが大切になる。 どうしても互換性のない変更を加えたくなる場合があるため、一般的にはエンドポイントにバージョン入れたりする方が好まれる。
すごい昔に読んだからもう古いのだけど、Webを支える技術とWeb API: The Good PartsはRESTfullを扱う本としてよかった。
Webを支える技術ではRESTを REST = ULCODC$SS と要約しているので理解しやすい。
| 記号 | 意味 |
|---|---|
| U | 統一インタフェース |
| L | 階層化システム |
| COD | コードオンデマンド |
| C | クライアント |
| $ | キャッシュ |
| SS | ステートレスサーバ |
ステートレスは最初に説明したことでサーバーをスケールアウトさせやすい。 キャッシュは重い処理でもステートレスならキャッシュを挟んだ効率化が簡単だといっている。 階層化システムはproxyとかを使って階層化することで負荷の分散などを行えることを指してる。 コードオンデマンドが主張しているのは、必要に応じてコードがサーバーから読み込まれるために配布済みアプリケーションよりもバージョンアップが容易ということだ。
Web API: The Good Partsではタイトル通りAPI設計について扱っている。 少し古くて認証にOAuth2.0を使っていたりと鵜呑みにはできないけど、JSONのデータ構造をフラットにするか階層化するか、エンベロープで全体を囲うか、レスポンスとして配列を許容するかオブジェクトで囲って提供するか、そしてHTTPステータスコードやHTTPヘッダの利用など判断に迷うところも扱っているので参考になる。
APIの仕様をOpenAPIで明記してそこからドキュメントとコードを生成させると、ドキュメントと実装のズレをなくせるので良い。
ひと昔はREST APIの仕様を記述する方法としてJSON Hyper-Schemaを利用する人も多かったけれど、今はOpenAPIに落ち着いている。 ただ最近はOpenAPIの元となったSwaggerの人たちとOpenAPIの間で分裂が起きているらしく悩むところ。
ちなみにOpenAPIではgRPCも定義できる。 (ちなみにMSAではgRPCを採用することが多い)
HTTP,HTTP/2のAPI用のIDLはOpenAPI,gRPC,GraphQLあたりを押さえておけば直近はよさそう。
CQRS
操作(コマンド)対象のモデルと参照(クエリ)するモデルのギャップが大きい時に使われるアーキテクチャ。 素朴に設計すると操作と参照は関連が強いためサブコンテキストや集約を共有すことが多くなる。
しかしこの2つのモデルにギャップが大きいときには、サブコンテキストや集約を分けてしまうと楽になる。
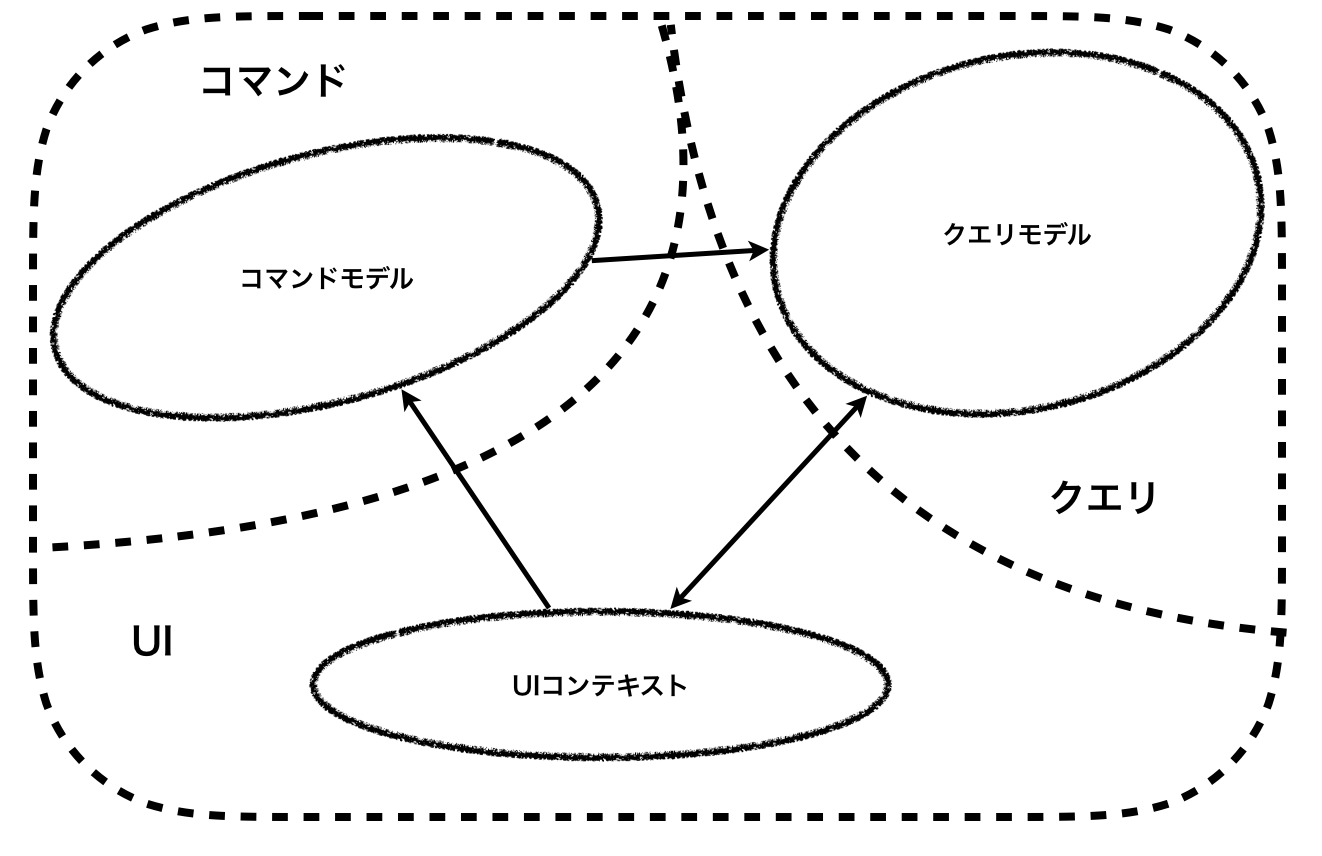 CQRS
CQRS
まず操作(コマンド)と参照(クエリ)それぞれに専用のサブコンテキストをつくる。 この2つのコンテキストを整合させる。整合させる方法には下のような手段が考えられる。
- 永続化機構を利用する
- RDBMSのVIEW
- RDBMSのMATERIALIZED VIEW
- CassandraのBATCH
- 更新イベントの伝搬(Pub/Sub)
- Observer pattern
- AWS SNS
- RabbitMQ with fanout
更新イベントを用いる場合はドメインイベントでモデリングする。 逆に永続化機構を利用する場合にはモデリングレベルでドメインイベントを実装する必要はない。
永続化機構を利用しても更新イベントの伝搬にしても遅延を許容する。 ただし非同期処理を受け入れるために、許容遅延と想定外の遅延や失敗時のリカバリの設計が必要になる。
イベント駆動アーキテクチャ
イベントの発行、検出と消費を中心としてソフトウェアを構成するアーキテクチャを表す。 そのため広く使われる。前述の CQRS もドメインイベント利用していたらイベント駆動アーキテクチャになる。
イベント駆動でサブコンテキストを連携させるときには、メッセージング(MQ, Pub/Sub)を利用することが多い。 このとき参加するコンポーネント(サブコンテキスト)はメッセージング基盤とメッセージの仕様について知っていないとならない。
ここでMQ, Pub/Subの違いをおさらいしておく。
MQ
MQではメッセージは1つのワーカーに届き処理される。 ワーカーが処理するメッセージの使用を定義して、不特定多数がメッセージを投入する。
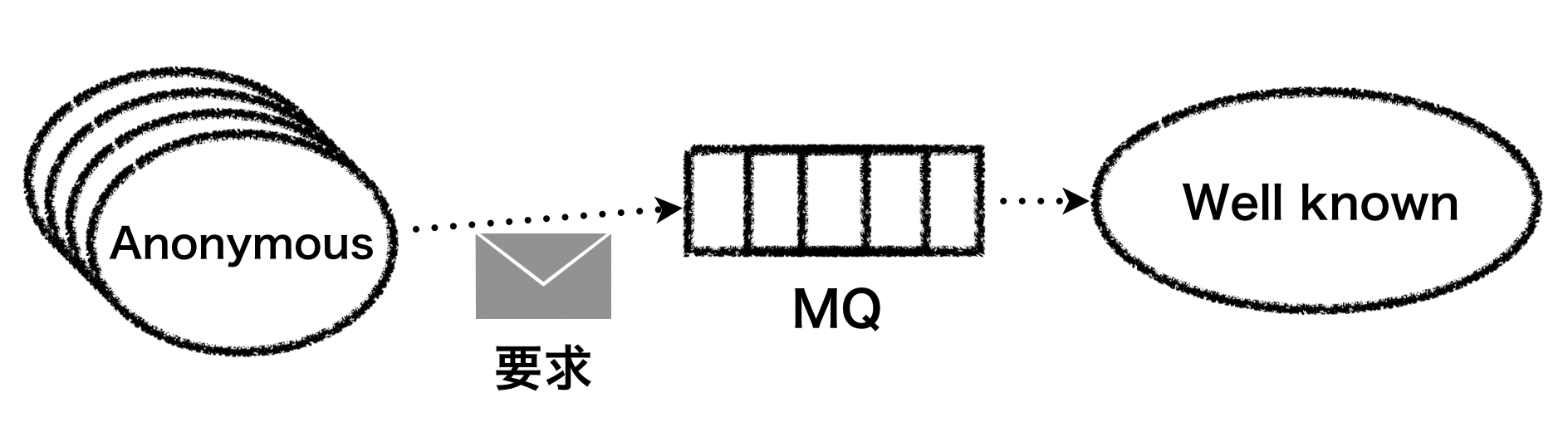 MQ
MQ
Pub/Sub
Pub/Subではトピックに向けて出版されたメッセージは不特定多数に購読される。 出版者がメッセージの仕様を定義して購読者がそれに依存する。
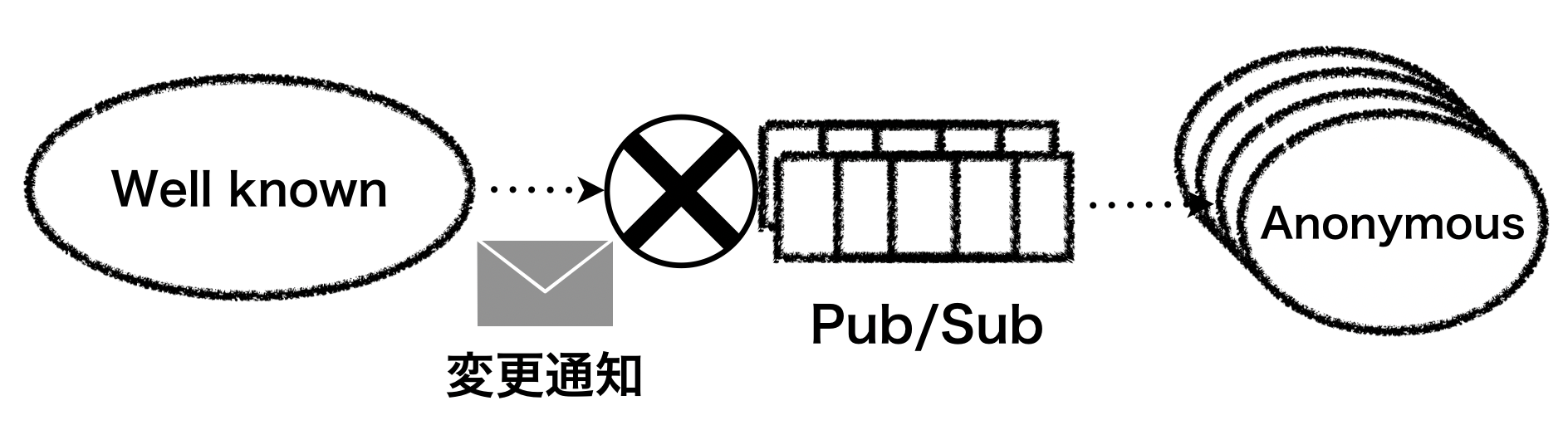 Pub/Sub
Pub/Sub
IDDD本ではイベント駆動の例として3つ紹介している。
| アーキテクチャ | 簡単な説明 |
|---|---|
| パイプとフィルタ | Unixシェルのパイプの様にイベントの伝搬で処理をデザインするアーキテクチャ |
| サーガ(長期プロセス) | イベントフローの完了通知を受けとるプロセスがいて全体のコントロールを行う |
| イベトソーシング | 操作コマンドで1つ以上の更新イベントを発行して永続化し参照側で統合する |
サーガではイベントの合流が起きる。そのためイベントには一意となる識別子が振られる。
イベントソーシングはWALログとかLSMtreeなどデータベースの内部で行われることをアプリケーションのレベルでやっているようなもので、分散した処理を安定させるために必要な設計パターンになる。 言及記事はたくさんある。
データファブリック・データグリッド
IDDD本でのアーキテクチャ紹介にデータファブリック・データグリッドの節が設けられていた。 大規模処理は分散処理基盤上で動かせるフレームワークなどを利用しましょうというだけだった。 冗長化とか継続クエリとかの話題も少しだけ触れていた。
Hadoop, Spark, Flink, APEX, Gearpump, Samza, Ignite, Geodeとかが提供してる計算リソースを使いましょうって話だった。
本で触れてたからここでも触れたけど、そんなに深いこと書いてないし面白くなかったし、ついでにいうとDDDと合わせて考えるのが難しかった。
感想
IDDD本について少しだけ書くと、DDDに閉じこもった話題に集中した方が良かったのではと思った。 色々と触れていて読んだり一貫しているか確認するのが辛い。壊れていて察してあげないと繋がらない箇所も多い気がする。
イベント駆動設計でコンポーネント間を疎結合にできる。そして非同期処理をつかえば処理遅延を隠せる。 でも非同期処理があると失敗や重複を前提にしないとならない。これは本当にたいへん。
ふと浮かんだ難所や注意点について並べる。
整合性を保ちたい処理は1コンポーネント(サブコンテキスト)の中で処理する。 そして状態管理は1つのミドルウェアで行う。
複数のミドルウェアで状態管理すると分散トランザクションが求められる。 とても高度なので可能なら結果整合性を許容する。
そして結果整合性のために、ミドルウェアをまたぐ処理や非同期処理は実行状態を管理する。 そのためにイベントに識別子(UUIDとか)を割り当てて対象処理の登録と完了を記録する。 さらに失敗や未完了の処理を再実行するように設計する。 また処理自体も冪等にするか重複実行されても結果が収束するようにする。
このためにイベントソーシングを採用することも考えられる。
イベントソーシングでは全ての処理が記録される。 参照時や適切なタイミングでスナップショットを計算するので順序に敏感な削除処理なども安全に扱える。
ただし履歴を残すことになるため、LSMtreeのマージ処理のような容量の管理が求められる。 (たとえクラウドストレージを使っても料金は発生するので最終的には対応が必要になる)
イベント駆動ではメッセージ基盤の可用性が大事になる。 最近はメッセージ基盤はPull型が主流。 その方がバックプレッシャーの管理をしやすくメッセージ破棄が少ない。 メッセージが破棄されると再実行ができなくなる。
バックプレッシャーを管理してメッセージの破棄を避けやすくするのは大事だがそれだけでは足りない。 下流の処理性能を負荷が越えるとメッセージは滞留するので一時的に維持するストレージが要求される。 そのためストレージ容量やNICのビットレートを渋ってはいけない。溢れたら回復不可能なのだ。
NICのビットレートやPPSは最大流量とメッセージサイズで考える。 ストレージのキャパシティは安全担保のために保持したい期間と流量で計算する。
他にもミドルウェアやサービスで特性が大きく違う。
たとえばRabbitMQがメッセージの保存にストレージを利用するかはメッセージの属性になる。 そのためメッセージ送信者が注意する必要がある。 (ただしRabbitMQはスループットが低めで最近はクラウドサービスも多いので選択することが少ないかもしれない)
インフラの運用や設計は大変なのでアウトソースしたくなる。 クラウドベンダーが各種サービスを提供しているので利用するのも良い。 ただキューを利用するアプリケーションの設計は絶対に必要となる。
何にせよアプリケーションを単純なコンポーネントの連携で実装するということは、連携のためのミドルウェアの選定と連携による複雑さが増える。 だからそれぞれのコンポーネントとミドルウェアの責任範囲を明確にする必要がある。