
Elasticsearch メモ
Elasticsearchを利用するにあたり勉強したり復習した事のメモ。
- HTTP, TCPで検索・分析を実施できる分散検索クラスタ
-
Elasticsearchは、様々なユースケースを解決する、分散型RESTful検索/分析エンジンです。 予期した結果やそうでないものまで検索できるようにデータを格納するElastic Stackの中核です。
ElasticsearchはHTTPで操作できるLuceneクラスタみたいなもので。構造型データ・非構造型データ・地理情報・メトリックなど広く扱える。 検索以外にもAggregation, Suggestionも提供されている。
今回は後で調べやすくなるように基本的な資料のリンクをまとめて概念を整理する。
その後で他のエコシステムとの繋がりや周辺ツールについて紹介する。 最後に運用上の注意事項や実際の利用の参考資料を載せる。
基本的な情報収集場所
下に各種資料が集められてるので公式ドキュメントの他に読んでおくといい。
- Elstic Blog
- Elasticsearch入門 – シリーズ –
- Elastic特集(Developers.IO)
- Hello! Elasticsearch.
- Cookpadのテックブログから検索
概念と設定ファイルとAPI
Elasticsearchの検索サービスはインデックス, ドキュメント, エイリアス, リポジトリ, スナップショットによって構成される。
サービスを提供するクラスタ内部の概念として、クラスタ, ノード, モジュール, シャード, ルーティングなどがある。
まずクラスタと提供されるサービスモデルを確認した後に内部モデルへと説明を進める。
サービスとクラスタのイメージ
用語をトップダウンで書いていくので説明で使った用語が後ろで説明されていたりするので注意。
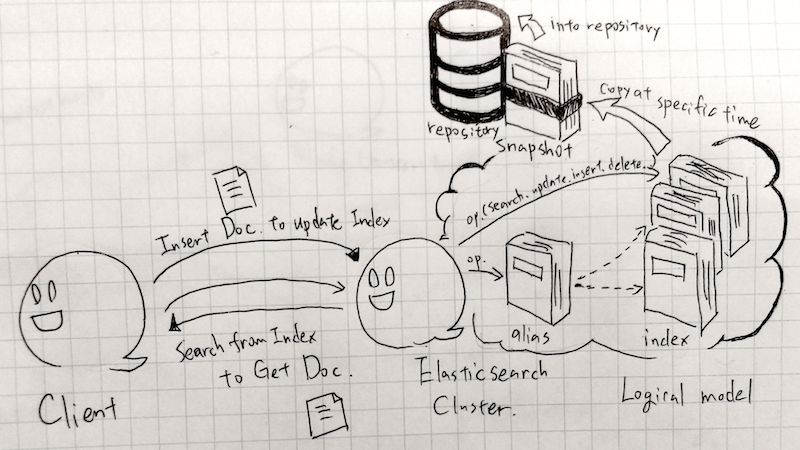
- クラスタ(cluster)
- 連携したElasticsearchノード(プロセス)の集合体で全体のこと。検索サービスなどを提供している。 複数のインデックスを提供している。 クラスタ内の全てのノードはインデックス名を知っており、外部のクライアントはクラスタ内のどこにアクセスしてもサービスを受けられる。 Elasticsearchでは同一クラスタ内の複数インデックスに対して横断検索できる。
- インデックス(index)
- ドキュメントの素早い参照を提供するデータ構造。 テーブルのように複数のフィールドを持つドキュメントが大量に格納される。 各フィールドのデータ型は全てのドキュメントで一致している必要がある。 RDBMSでいうデータベース的な感じで説明されているのを見かけるがどちらかというとテーブルに近い。 インデックスはドキュメントを挿入・削除する事によって更新される。 多くのインデックスはドキュメントの本文も格納する(設定による)。
- フィールド(field)
- インデックスに格納されたドキュメントの項目。 フィールド名とテキストによって構成される。各フィールドはデータタイプ(data type)を持つ。
- データタイプ(data type)
- フィールドのデータ型で事前に準備される。 フィールドが複数のデータタイプを持つマルチフィールドとして複数のデータタイプを持たせることも可能。 (テキストデータを自然言語処理する方式などを複数選択するなどの場合に用いる)
- テキスト(text)
- フィールドに格納されているデータ。また解析された物をターム(term)と呼ぶ。
- エイリアス(alias)
- インデックス(を束ねたもの)に対する別名。 インデックスに直接アクセスすると更新反映のタイミングに柔軟性がなくなったりする。そのため柔軟性を確保したり保守性を高める目的で利用する。 単なる別名を与えるだけではなく自動的に追加処理(ルーティング・フィルタリング)を行うなど論理的なプロキシとして機能する。 またロールオーバーインデックス(rollover index)と呼ばれるログローテート的な機能を実現する事もできる。
- ドキュメント(document)
- 検索対象のデータ。RDBMSのレコードに例えられたりする。 ElasticsearchではJSON形式で挿入できる。ドキュメントはインデックス内でユニークなIDを持つ。これは挿入時に明示的または暗黙的に決定される。 ドキュメントのインデックスへの論理的な関連付け(解釈方法)をマッピングと呼び、内部の物理的は配置の決定をルーティングと呼ぶ。 これらの対応付けは自動・手動のどちらでも定義できる。
- スナップショット(snapshot)
- 特定時刻のインデックスのコピー。後で復元したりするのに用いる。
- リポジトリ(repository)
- スナップショットを保存する場所。 クラスタを構成するマシンのファイルシステムやプラグインを用いる事でS3などの外部サービスを利用できる。
ドキュメントを中心にクラスタ内部とドキュメントを眺める
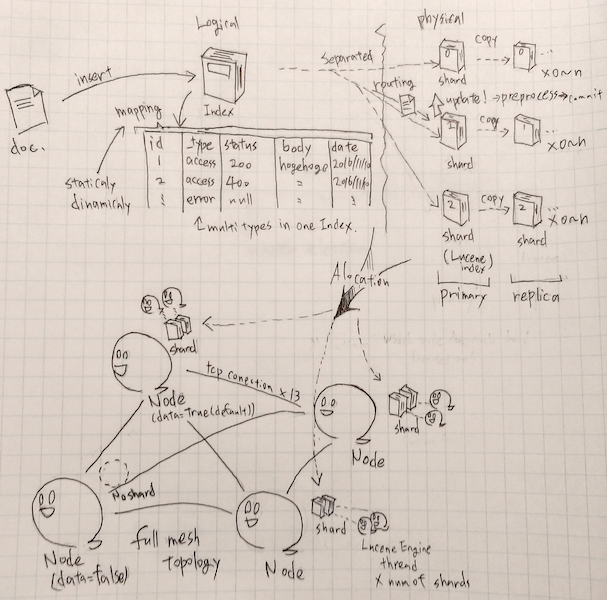 inserting document into index with mapping and routing to a shard which is alocated on a node.
inserting document into index with mapping and routing to a shard which is alocated on a node.
- マッピング(mapping)
- ドキュメントとインデックスの論理的な関連付けをマッピングと呼ぶ。 事前に定義する静的マッピングの他に、フィールドの解釈ルールを定義して自動的に判断させる動的マッピングも提供されている。 事前に何も定義しない場合、デフォルトで定義された解釈ルールを通して動的マッピングが行われる。 静的マッピングは同一インデックスに複数定義する事ができ、1つの静的マッピング定義がドキュメントタイプに対応する。
- ドキュメントタイプ(type)
- ドキュメントがインデックスへ格納された際に付加されるドキュメントの分類情報。 静的マッピングにより定義できる。インデックス内で_typeフィールドが付加される事で実現している。 RDBMSでテーブルという例えを見るがどちらかというと単に自動的にフィールドを付加するだけ。 そのため同一インデックス内の同一フィールドは異なるドキュメントタイプでもデータ型の一致が必要。
- シャード(shard)
- インデックス(index)の実体。Elasticsearch_のインデックスは複数のLuceneインデックスで構成されている。それぞれのLuceneインデックスをシャードと呼ぶ。 シャードはマスターとして扱われる**プライマリシャード(primary shard)と冗長性確保のためのレプリカシャード(replica shard)**の2種類が存在する。 インデックスの分割数(プライマリシャードの数)はインデックス作成時に決定され、指定されない場合は5つになる。この内部的に必要なシャードの数をシャード数と呼ぶ。 一方、レプリカシャードの数は動的に変更が可能で0以上の任意の数を設定できる。プライマリシャード当りのレプリカシャードの数をレプリカ数と呼ぶ。
- ルーティング(routing)
- インデックスに挿入されたドキュメントをどのシャードに格納するか決める事をルーティングと呼ぶ。 ルーティングは様々な方法で指定が可能になっている。基本的にIDを元にコンシステントハッシュを用いてシャードを決定する。 しかし、インデックスの設定で特定フィールドをIDの代わりにルーティングキーに指定できる。 また、エイリアスのルーティングを指定する事も可能で、さらに挿入・検索といった問い合わせの時に_routingパラメタを用いて強制する事もできる。
- ノード(node)
- Elasticsearchクラスタを構成するプロセス。 指定しないとMarvelヒーローの名前がランダムに選択される。 内部では各種モジュールに分割されている。モジュールはノードに必要な機能を提供している。 特にNode Clientモジュール, Tribe nodesモジュール の設定によってノードは4種類の役割(Master-eligibleノード, Dataノード, Ingestノード, Tribeノード)に分類される。 多くの場合、クラスタ内のノードは上記のTribeノード以外の役割を全て担う。 (Tribeノードは大規模なクラスタを組み際に利用する可能性がある程度であまり使われない雰囲気を醸し出している)
- アロケーション(alocation)
- シャードをノードに配置する事をアロケーションと呼ぶ。 基本的にデータノードの中で負荷が分散されるように自動的に選択される。 特定のノードを指定して配置したり避けるように指定したりといった設定が可能で、特定ノードにある指定したシャードを別の指定したノードに移動するなど直接的な操作も提供されている。
- モジュール(module)
- ノードはモジュールにより構成される
- プラグイン(plugin)
- 機能拡張を行うモジュールで様々なものが提供されている
ノードの役割とクラスタの構成
ノードの参加からクラスタ維持に関する項目を中心に整理する。
接続方法
Elasticsearchへの接続方法はHTTP, TCP(NodeClient, TransportClient)の3つある。 クラスタを構成するノードはNodeClientを利用する必要があり、これは既存クラスタ内のノードと共に full mesh topologyを構成する。 検索サービスを利用したいだけのクライアントなどは、HTTP, TransportClientを利用する。 クライアントは検索サービスの利用の他にクラスタの管理機能も利用できる。
ノードの種類とモジュール
Elasticsearchのノードは大きく4つの属性によって役割を持っている(一般的にはそれぞれのノードが全ての役割を担いながらクラスタを形成する)。
- master-eligible ノード
- masterノードに選出される可能性を持ったノードであり、masterノードとの合意形成にも関わる。
設定ファイルで
node.master = trueとなっている。 - master ノード
- master-eligible ノードの中で選出されたノードでクラスタ内で1つ存在する。
- data ノード
- インデックスなどのデータ実体を保持するノード。 設定ファイルで
node.data = trueとなっている。 - ingest ノード
- インデックス更新の前に事前処理を定義している場合にその事前処理を実行する。
Logstash, fluentdなどで行っているフィルター・変換処理などを分散して行う事が出来るようになる。
設定ファイルで
node.ingest = trueとなっている。 - tribe ノード
- 複数クラスタへ接続して1つに繋げる事が出来るノード。 パフォーマンス面、運用面、障害発生時のリスクをどう考えるかによって検討するのが良さそう。 Tribe Node 必ずしも必要ではありません。 複数のClusterを横断して検索する要件があれば採用すれば良いとの事。
Ping & Join
ノードがクラスタに参加するまでと参加してマスターノードが決まった後について公式資料からコピペレポートを作ってみる。
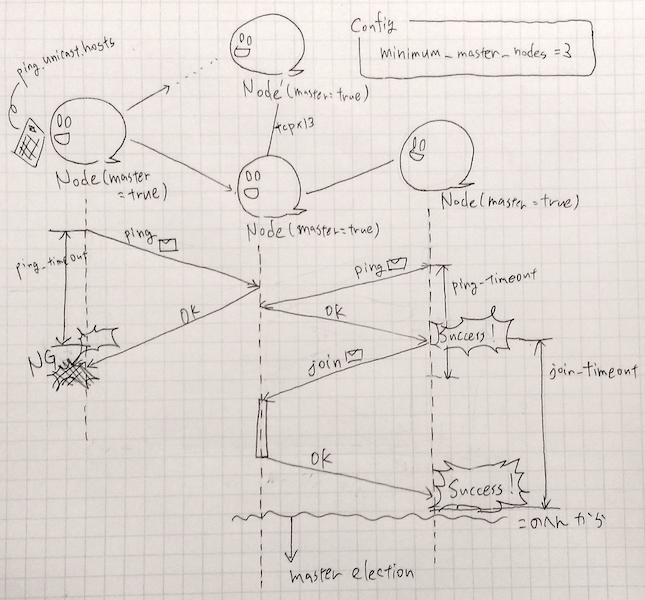 ノードの参加までとマスター選出の実行
ノードの参加までとマスター選出の実行
- ノードはdiscovery.zen.ping.unicast.hostsに記載されたホストに向かってPINGを行う。(v2.0以降はノードディスカバリにunicastしか提供しない)
- PINGの成否はdiscovery.zen.ping_timeout の値でタイムアウトで判断される。成功するとJOINが行われる。
- JOINの成否はdiscovery.zen.join_timeout の値でタイムアウトで判断される。
こうして同一クラスター名を共有するノードが1つのクラスタに参加していく。
Master election
クラスタの設定管理はマスターによって行われる。 不整合などに対応するためにマスターが存在しない場合には機能制限がある。 ただし設定によってマスターが存在しても不整合は発生しうるので注意が必要。
マスターの選出はdiscovery.zen.minimum_master_nodes で設定された数値以上の master-elilgible ノードがクラスタに参加していないと始まらない。 マスターが決定しないと以下の設定項目に依存した機能制限が生じる。
- discovery.zen.master_election.ignore_non_master_pings
- trueの場合には、master-eligible node 以外からのPingを無視する(default: false)
- discovery.zen.no_master_block
- all : 全ての操作が失敗する write : 書き込み操作が失敗する
Fault Detaction & Cluster state updates
マスターの存在するクラスタでは、障害検知とクラスタの状態管理が行われている。 マスターが各ノードへPingを飛ばして障害検知を行う。 また各ノードは互いに接続しておりこれをfull mesh topologyと呼ぶ。 ノード間の接続では用途の決まった13のTCPコネクションが張られている。
- discovery.zen.fd.ping_interval
- 障害検知のためにmasterから他のノードへ送られるpingの頻度
- discovery.zen.fd.ping_timeout
- 障害検知に使われるpingのタイムアウト設定
- discovery.zen.fd.ping_retries
- 障害検知に使われるpingの失敗で使わるリトライ数
マスターが他のmaster-eligibleノードへ確認を行いdiscovery.zen.minimum_master_nodes 以上の合意を得られないと拒否する事でクラスタの状態変更における一貫性を保っている。 確認ではdiscovery.zen.commit_timeout で定めたタイムアウトを用いて成否を判断する。 状態管理機能はAPIとしてクライアントから利用できる形で提供されている。
検索サービスについて
基本的なチュートリアルとして下を試せば基本的な事には慣れられる雰囲気があった。
- 第7回 Elasticsearch 入門 API の使い方をハンズオンで理解する 〜前編〜
- 第8回 Elasticsearch 入門 API の使い方をハンズオンで理解する 〜後編〜
- 実践!Elasticsearch
検索各種のAPIには共通オプションがある。また複数のインデックスに対しても横断検索が出来る。 インデックスの更新反映は準リアルタイムに行われるが検索性能悪化とのバランスが取られる。
Suggester・スナップショット機能・Shrink Index機能, Reindex機能, スクロールAPI, Pipeline Aggregationなどの機能がある。 またParent-Children Relationshipという機能で複雑なモデリングも可能になっているうえAggregation機能も充実している。 正直まだ機能の全貌は見渡せてないし慣れてもない。実践してみた系の記事が沢山あるので読んだ。
- Parnet-childを使ってみた
- リポジトリとスナップショット
- 触って身に付く elasticsearch 1.0.0 の Snapshot と Restore 操作メモとスナップショットの仕組みの考察
- Shrink Index
- マッピング定義漏れなどの対応に利用している例
- Reindexが登場!
- [elasticsearch2.0] Pipeline Aggregationを試す -Avg/Max/Min/Sum Aggregation
- Elasticsearch 2.0.0 で導入予定の Pipeline Aggregations が便利そうなので自分なりにまとめてみたよ
- ElasticsearchのIngest Nodeを試してみた
マッピングについて
- インデックスにドキュメントをマッピングして利用する
- メタフィールド(_index, _type, _id, _source, _all, ..)とフィールドで構成される
- デフォルトではドキュメントが投入されると自動的に作成される
- 自動作成のルールを定義できる
- 自動作成は停止できる
データタイプ(data type)について
- マッピングの各フィールドの型に相当する
- 次のようなタイプが存在する(text, keyword, long, integer, short, byte, double, float, date, boolean, binary, array, object, nested, geo-point, geo-shape, ip, completion, token_count, murmur3, mapper-attachments, percolator type)
- date型はJSON内の文字列表現と公式フォーマットに従って対応付けられる
- fields キーワードを用いること同一フィールドに複数の型や解析方法を設定できる
Kibana+Elasticsearchで文字列の完全一致と部分一致検索の両方を実現する ではmulti fieldsを使って完全一致・部分一致を利用できる様にしており Dynamic templateの設定で自動的にドキュメント内のstringの項目が自動的に対応する様にしている。
エイリアス
Elasticsearchではインデック(を束ねたもの)に別名を与えられる。その別名をエイリアス(Alias)と呼ぶ。これによってクライアントのアクセスをサーバー側でコントロールできる。気になった特徴としては以下がある。
- 複数のIndexをまとめて対象にできる
- エイリアスの変更操作は複数操作を同時に反映させることができる
- エイリアスでは向き先のインデックスへフィルターを適応させることができる
- エイリアスではインデックスへのルーティングを強制することができる
上の特徴の活用例が幾つか紹介されている。
- 任意のタイミングで新しいインデックス情報を一気に追加する
- 停止せずに再作製したインデックスに切り替える
- 用途別にエイリアスを提供する
などが紹介されていた。 「停止せずに再作製したインデックスに切り替える」はとても魅力でオートスケールに繋げられそうと思った。 elasticsearchでダウンタイムなしでインデックスのマッピングを切り替える などの記事も存在する。 またCookpadも無停止更新について書いている。
更新系はエイリアス経由では出来ないのか気になる。 できる場合は更新・削除を無停止に出来る例になっていなかった。 そのため上記の検証を行って必要な場合は更新・削除が可能な方式を考えてみたのでそれも検証したい。
またroll-over-indexによって定期的・一定サイズでインデックスを切り替えることが出来るらしい。同一エイリアスで古いインデックスを参照できるか確認しておきたい。
Index vs. Type(結論の翻訳)
Index vs. Typeを参考に読んでた。 結論部分のみ翻訳すると下の4つ。
- Parent/Childを利用するか?
- 利用するならば2つのタイプは同一インデックスに含まれていないとならない
- ドキュメントは似たマッピングを持つか?
- そうでないのであれば異なるインデックスを利用した方が良い
- もし各タイプのドキュメントが大量に存在する場合は、Luceneインデックスのオーバーヘッドを簡単に償却できるため、必要であればデフォルトの5よりも小さいシャードを利用しつつ安全に複数のインデックスを利用できる
- そうでない場合、ドキュメントを同一インデックス内の異なるタイプに投入すると考えることができる
Luceneはスパースなインデックスを効率良く圧縮できない。 修正によって緩和されるらしいが、やはり同一インデックスに大きく異なるタイプのドキュメントの格納は効率が悪い。
関連ソフトウェア
Client
たくさんの言語で用意されている。 Go言語ではElastic: An Elasticsearch client for the Go programming language.が使ってみた感じ手軽なのと分かりやすくて良さそうだった。
保守・運用ツール
ベンチマークツールとしてRallyが公式で発表されている。 また保守に便利なCuratorというクライアントがある。 日本語の記事もあるし読む感じ手軽に使えそうだった。
OpenStack
Troveに対応しているみたい。
Hadoop
Elasticsearch-Hadoopを使うと Elasticsearch, Hadoop, HDFS間でのデータ・クエリのやり取りやバックアップが 簡単になるようです(ちゃんと読んでない)。
用途特化
機能拡張
プラグインは沢山ある。 公式の他にも紹介記事があるので参考に。 導入には下のコマンドでインストールする。1,2,5系でコマンドが異なる。
|
|
- X-Pack
- 公式の拡張プラグイン。基本機能は無償ライセンスで利用できる。
- ElastAlert
- インデックスの内容・変化を利用した通知機能(developed by Yelp)
- Sensu
- WebUI with Query Editor
- Marvel>Introduction
- Marvelの紹介と第一印象
設定などの注意点
下は最低限チェックする。設定・チューニングについてはチェック表とかフローチャートを作っておきたい。 それにはパフォーマンスモデルを考えてベンチ取る必要がありまだ出来てない。
- ノード名は
${HOSTNAME}にすると分かりやすい - network.hostlocalhost では他のホストから接続できない
- discovery.zen.ping.unicast.hosts で必要な接続先を明示する
- discovery.zen.minimum_master_nodes は全(Master-eligible)ノードの過半数を指定
- ヒープは物理メモリの50%より低く設定する
- JVMのメモリを32GB以上にしないようにヒープ上限は30GB以下にする
- ファイルディスクリプタを大量消費するので増やしておく(32K, 64Kなど)
- 仮想メモリマップ数を多めにとっておく
- SSDを利用する
- インデックスをリモートマウントされたストレージに配置しない
- 複数のSSDデバイスをpath.dataに複数のパスとして登録する
-
- シャード数は大きくしすぎない(シャード数に応じてランダムI/Oが増加する)
- (目安は1シャードあたり1GB程度だがベンチマークで事前の検証は必須)
- シャード数あたりのドキュメント数上限があるのでキャパプラに気をつける
- レプリカが多いと書き込み待ち時間が長くなるので更新時は減らす(0など)
- インデックス内に複数タイプのドキュメントが格納されると利用メモリが大きくなりがちなので分割する
- store, index属性をfalseにする事でインデックスサイズを抑える
- 横断検索が不要な場合は*_all* 項目は利用しない
- ハイライト・部分更新などを利用しない場合は*_source* 項目は利用しない
- IDにこだわりがなければオートIDを利用する
- 暗黙的なマッピングによる不要なフィールドの作成を避ける
- ログ解析など全文検索用途でなければnot_analyzedを設定する
- bulkAPIの利用時は処理が早く済むように一時的にインデックスの更新反映をギリギリまで行わない設定にする
-
- Elasticsearchの更新リクエスト内部キューを溢れさせないように注意する
- 溢れるとデータは破棄される(STATUS CODE: 429)