
メトリクス可視化をやってみた(Diamond + InfluxDB + Grafana)
Diamond + InfluxDB + Grafanaでメトリックス集計した。無理やり入れた感が否めない。
今日の方針
- 収集にはDiamondを使う
- Diamondはvirtualenvのpython27環境にpipでインストールする
- NginxのメトリックスもDiamondで収集する
- InfluxDBのGraphiteインタフェースを利用する
- 可視化はGrafanaを利用する
- Grafanaのユーザー管理はGithub OAuthを利用する
Diamon
![]()
Pythonで書かれたメトリックスの収集・転送を行うエージェント。 メトリックスの収集を行うcollectorと転送を行うhandlerによって構成されている。
ソースコード
簡単にソースコードを追った。
- bin/diamond
-
プログラムのエントリポイント オプション処理, デーモン化, フォーク処理, シグナルハンドラ設定, サーバー起動処理
- diamond/server.py
-
Server定義を行っている
- diamond/handler/*
-
データ転送に用いるhandlerのプリインが各種置かれている
- /usr/share/diamond/collector/*
-
データ収集に用いるcollectorのプリインが各種置かれている
server.py:Server.run の処理
- Config処理
- collectorロード
- handlerロード
- multiprocessingを使ってhandler起動
- 収集開始(無限ループ突入)
- multiprocessingを使ってcollector起動
設定ファイル
通常は_/etc/diamond/diamond.conf_ が設定ファイルとして読み込まれる。
コレクター・ハンドラーの有効化
設定項目collectors_path, handlers_config_path によって
collector, handlerの読込先ディレクトリが定義されている。
そのため、これらの指定ディレクトリにpythonコードを配置すればロード可能となる。
ロードするかの設定は各プラグインそれぞれデフォルトでenabled = Falseのため無効となっている。
そのため実際に有効化するには設定ファイルでenabled = Trueとする必要がある。
実際には以下の2つの方法がある。
diamond.confを書き換える方法
通常の設定ファイルを変更する。
|
|
プラグイン用設定ファイルを作成する方法
設定ファイルに指定されているプラグイン用のディレクトリにプラグイン用の設定ファイルを配置する。 collectorについてはdiamond-setup というテンプレート生成コマンドが準備されている。
設定ファイル用ディレクトリを指定する項目はそれぞれ collectors_config_path,handlers_config_path の2つ。
|
|
インストールと設定と起動
python27を使う。
|
|
python26 使ってしまったりと不都合があったため*/etc/init.d/diamond* を書き換える。
|
|
実行ユーザーを準備する。
|
|
はじめにNginx側から提供するように監視用のエンドポイントを設定する。
|
|
DiamondのNginxCollectorを有効にする。 先ほど設定したエンドポイントはNginxCollectorのデフォルト設定に合わせてあるため有効にするだけで良い。
|
|
Diamondを起動する
|
|
デバッグログの出し方
設定ファイルに以下を設定する。
|
|
InfluxDB
![]()
Goで書かれたMITライセンスの時系列データベース。
- 書き込み速度と高可用性に最適化しようとしている
- APIはHTTP(S)をサポートしておりSQL-likeなクエリ言語も提供している
- Graphite, collectd, OpenTSDBなど他のプロトコルによる入力もサポートしている
ソースコード
簡単にソースコードを追った。
| プログラム | コード箇所 |
|---|---|
| influxd(server) | ./cmd/influxd/main.go |
| influx(client) | ./cmd/influx/main.go |
influxd(Server)の構造
- ./cmd/influxd:Main
-
コマンド全体プロセス
- サブコマンドのディスパッチ
- サーバーが停止しないようにブロックする
- ./cmd/influxd/run:Command
-
サブコマンド(
influxd run)に対応する サーバーの設定読み込み - ./cmd/influxd/run:Server
-
サーバー本体に対応する構造体
- NewServer()
- サーバー機能に必要なセットアップを一通り済ませる
- ログファイル, meta:Client, その他のリソース確保
- Open()
- サーバー提供 appendXxxxService()などを用いて提供サービスを読み込み実行
- ./service/*
-
各種サービス
- meta:Client はNewServerで読み込まれる
- 他はだいたいOpenで読み込まれる
インストールと設定と起動
|
|
DiamondがInfluxDBのインタフェースに転送しようとしたところ失敗したため。 Graphite互換インタフェースを有効にする。
|
|
起動する。
|
|
Grafana
![]()
時系列データ・メトリックスの問い合わせ・可視化ツール。
- サポートしている時系列データソースが多い : Graphite, ElasticSearch, Cloudwatch, Prometheus, InfluxDB, OpenTSDB, KairosDB
- 認証機能が充実している : LDAP, BasicAuth, Auth Proxy
- 注釈を付けられる
- スナップショットが取得でき他メンバーに共有できる
ソースコード
読んだ感じ、キャンセレーションにcontextを既に使っていたりとGo言語でWebアプリ書く参考になりそうだった。
- ./pkg/cmd/grafana-server/main.go
-
エントリポイントでserver.Start()している
- ./pkg/cmd/grafana-server/server.go
-
web frameworkとしてmacaronを使っている
また.editconfigがあった。初めて知った。 人間関係を壊したくないのでeditorconfig/editorconfig-vimをインストールします。
インストールと設定と起動
|
|
GitHubでのOAuth認証を有効にする。
GitHub上で Settings > OAuth Applications の項目からアプリケーションを登録する。
grafana側でauth.githubを有効にする。 設定項目を見るとauth_url, token_urlが存在するのでGitHub Enterpriseも使えそう。 他にも認証オプションは豊富。
|
|
起動する。
|
|
結果
対象サーバーはiptablesでポート閉じまくっているのでトンネルを掘って利用する。
|
|

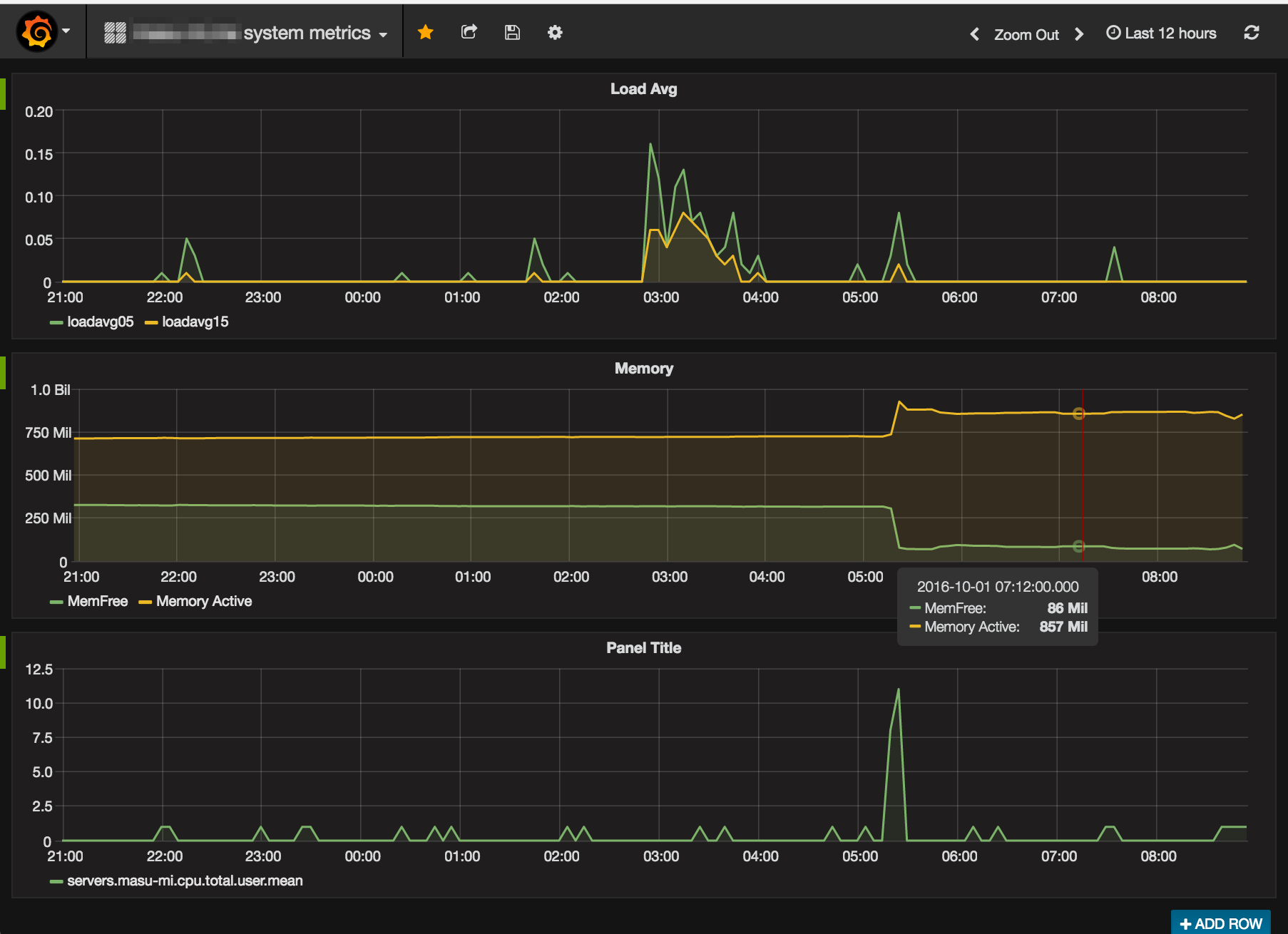
アクセスしてmetrixを設定するとちゃんとグラフを見ることができた。
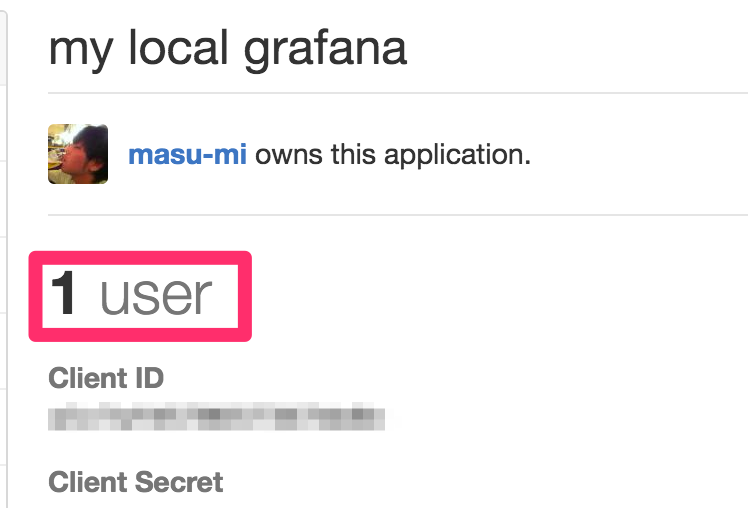
ちゃんとGitHub上で認証ユーザーが1人増えていることも確認できた。
競合製品が多くこれから一歩ずつ知識を深め広めて検討できる状態にしたい。 一旦は比較対象になる組み合わせで稼働させられてよかった。