
dstat プラグインの書き方
監視したい項目をdstat pluginにしておけば、fluent-plugin-dstat でどこにでも飛ばせるしdstatでCLIも存在するしcsvにも吐き出せるしでとても便利な気がした。 だけど公式ドキュメントにもpluginの書き方が見当たらなかった。 そのため、基本的な書き方をまとめておく事にする。
pluginの配置場所
dstatのpluginは以下のディレクトリに配置した。
dstat_plugin_snake_case.pyが読み込まれる。
~/.dstat/配下に置くのが手軽で影響範囲も少なくて良さそう。
- ~/.dstat/
$(which dstat)/plugin/- /usr/share/dstat/
- /usr/local/share/dstat
プラグインを書いてみる
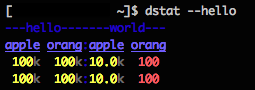
以下のファイルを.dstat/dstat_hello.py に配置してdstat - helloを実行してみる。
|
|
プラグインの構成要素
soファイルでプラグインを作る事も可能だがここではpythonで書く事を想定する。
plugin内ではdstat_pluginクラスを作成する必要がある。
最低限定義すべきメソッドは__init__, extractの2つ。
プラグインのイベントフック
各イベントの意味付けや仕様は後述する。
ロード時の実行内容
- dstat_plugin classのインスタンス生成
- prepare(): ユーザー定義しない
- discover(): データ取得可能か判断する(mysql用pluginなど)
- vars() or vars: 必須: 後述する
- name(): 必須: 後述する
- nick() or nick: ユーザー定義可能: 後述する
実行中のイベント
- extract()
プラグインの種類
プラグインの扱うデータの構造により大きく2つに別れる。
- 階層を持つもの
-
cpuやdiskの様に複数の出力元が存在しグループが複数存在する
- 階層を持たないもの
-
loadaverage の様に出力元が単一
各イベントフックの仕様
dstat_plugin pluginの読み込み開始にインスタンス生成される。
check()で最低限の健全性を確認しprepare()メソッドで初期設定が行なわれる。
そのためインスタンス生成後に以下が定義されている必要がある。
| フィールド | 意味 |
|---|---|
| name | dstatのヘッダの一番上の行に当たるブロックの名前 |
| vars | (項目名の一覧 or それを返却する関数) |
| nick | 各項目の名前 |
| type | 出力される値のタイプ |
| width | 出力されるカラムの幅 |
| scale | 値のスケールを入れる、まだ理解出来てない |
| cols | nickの項目数、設定値による挙動を理解出来ていない |
値の中身
- type メンバ
-
s: 文字列, d: 整数, f: 浮動点数, p: 割合(パーセンテージ)
- scale メンバ
-
値のスケールを設定する(デフォルトは1000)1024だとByteで末尾にBが付いたりする 1000 or 1024だとk, Mなど接頭辞が付く
name, vars, nickは階層を<持つ/持たない>により内容が変わるため別説で記述する。
name, vars, nick の3項目とデータ構造の関係
name, vars, nickの3メンバはデータ構造に合わせて内容が変わる。 これは実行中に呼ばれるextractメソッドの挙動と整合性を保たねばならない。 この3項目はメンバがデータ構造に合わせた値でも、そのような値を返す関数でも動く。
nameはプラグインの一番上のタイトル部分を担当
- 階層を持たない場合
-
タイトルに当たる文字列 or そのような文字列を返す関数
- 階層を持つ場合
-
タイトルを格納したリスト・タプル or そのようなリスト・タプルを返す関数
varsはプラグインの第1階層の属性名を担当
- 階層を持たない場合
-
項目名にあたるリスト or そのようなリストを返す関数
- 階層を持たない場合
-
サブグループ名にあたるリスト or そのようなリストを返す関数
nickは実際に表示される値の項目名を担当する
- 階層の有無にかかわらず
-
項目名にあたるリスト・タプル or そのようなリスト・タプルを返す関数
extract() の仕様
extract()は実行中に呼ばれ出力する値をメンバ変数valに辞書として格納する。 valが出力に用いられるが、中間値としてメンバset1, set2 を使って次回に値を引き継ぐ事も可能。
階層を持たない場合
辞書valにはvarsに含まれる名前をキーに値を格納する。
|
|
階層を持つ場合
辞書にはvarsに含まれる名前をキーにnickと対応する様にリスト・タプルを格納する。
|
|
便利メソッド
| メソッド | 機能 |
|---|---|
| open | 複数のファイル名を渡すと登録されファイルハンドラを保持する |
| readlines | 保持されているファイルハンドラを順々にreadlinesするgenerator |
| splitlines | 保持されているファイルハンドラのreadlines結果をsplitして結果を返してくれる |
他にもtitle, colwidthなど整形や出力に関わるメソッドが定義されていた。
dstatのコード内のdstat_cpuなどを読むと、使い方が分かる。
これでdstatのプラグインを簡単に作れる。めでたしめでたし。